

这6种方法分为2大类:一大类方法是SGD及其改进(加Momentum);另外一大类是Per-parameter adaptive learning rate methods(逐参数适应学习率方法),包括AdaGrad、RMSProp、Adam等。
当训练数据N很大时,计算总的cost function来求梯度代价很大,所以一个常用的方法是计算训练集中的小批量(minibatches),这就是SGD。
minibatch的大小是一个超参数,通常使用2的指数,是因为在实际中许多向量化操作实现的时候,如果输入数据量是2的倍数,那么运算更快。
SGD的缺点:
(1)Very slow progress along shallow dimension, jitter along steep direction
(2)到local minima 或者 saddle point会导致gradient为0,无法移动。而事实上,saddle point 问题在高维问题中会更加常见。
参数:
在SGD中,gradient类比成速度(矢量),learning rate类比成时间。Momentum update(动量更新)就是我不仅要看当前时所在位置的速度向量,还要看上一步的速度(梯度),两个向量相加才是我想要的速度矢量:
在这里引入了一个初始化为0的变量v和一个超参数mu。说得不恰当一点,这个变量(mu)在最优化的过程中被看做动量(一般值设为0.9),
但其物理意义与摩擦系数ρ更一致。这个变量有效地抑制了速度,降低了系统的动能,不然质点在山底永远不会停下来。通过交叉验证,这个参数通常设为[0.5,0.9,0.95,0.99]中的一个。
和学习率随着时间退火类似,Momentum 随时间变化的设置有时能略微改善最优化的效果,其中动量在学习过程的后阶段会上升。一个典型的设置是刚开始将动量设为0.5而在后面的多个周期(epoch)中慢慢提升到0.99。
PyTorch中的 SGD with momentum 已经在optim.SGD中的参数momentum中实现,顺便提醒一下PyTorch中的momentum实现机制和其他框架略有不同:SGD with Momentum/Nesterov
Nesterov Momentum实际上是拿着上一步的速度先走一小步,再看当前的梯度然后再走一步。
Nesterov Momentum 与 普通Momentum 的区别: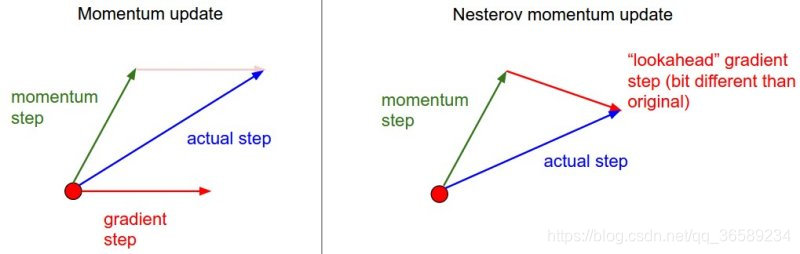
既然我们知道动量将会把我们带到绿色箭头指向的点(x + mu * v),我们就不要在原点(红色点)那里计算梯度了。使用Nesterov动量,我们计算x + mu * v的梯度而不是“旧”位置x的梯度。
在PyTorch中,通过参数nesterov=True 来实现Nesterov Momentum。
AdaGrad、RMSProp、Adam都属于Per-parameter adaptive learning rate methods(逐参数适应学习率方法):之前的方法是对所有的参数都是一个学习率,现在对不同的参数有不同的学习率。
注意,变量cache的尺寸和梯度矩阵的尺寸是一样的,还保持记录每个参数的梯度的平方和。
cache将用来归一化参数更新步长,归一化是逐元素进行的。注意,接收到较大梯度值的权重更新的学习率将减小,而接收到较小梯度值的
权重的学习率将会变大。
有趣的是平方根的操作非常重要,如果去掉,算法的表现将会糟糕很多。用于平滑的式子eps(一般设为1e-4到1e-8之间)是防止出现除以0的情况。
Adagrad的一个缺点是:在深度学习中单调的学习率被证明通常过于激进且过早停止学习。
PyTorch中的用法:
参数:
RMSProp简单修改了Adagrad方法,它做了一个梯度平方的滑动平均(it uses a moving average of squared gradients instead).
在上面的代码中,decay_rate是一个超参数,常用的值是[0.9,0.99,0.999]。
x+=和Adagrad中是一样的,但是cache变量是不同的。因此,RMSProp仍然是基于梯度的大小来对每个权重的学习率进行修改,这同样效果不错。但是和Adagrad不同,其更新不会让学习率单调变小.
个人觉得,RMSProp相较于Adagrad的优点是在鞍点等地方,它在鞍点呆的越久,学习率会越大。
PyTorch中的用法:
参数:
Adam看起来像是RMSProp的Momentum版,简化代码如下:
Adam看起来真的和RMSProp很像,除了使用的是平滑版的梯度m,而不是用的原始梯度向量dx。
论文中推荐的参数值eps=1e-8, beta1=0.9, beta2=0.999。
在实际操作中,我们推荐Adam作为默认的算法,一般而言跑起来比RMSProp要好一点。但是也可以试试SGD+Nesterov动量。
完整的Adam更新算法也包含了一个偏置(bias)矫正机制,因为m,v两个矩阵初始为0,在没有完全热身之前存在偏差,需要采取一些补偿措施。
PyTorch中的用法:
参数:
参考莫烦教程
?

epoch: 1/16,steps:832/1000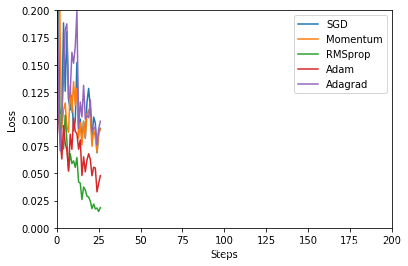
epoch: 8/16,steps:32/1000
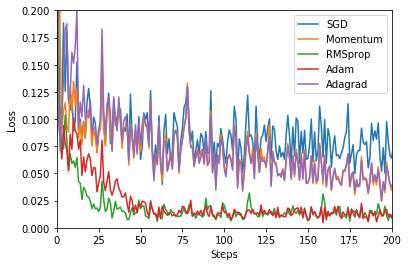
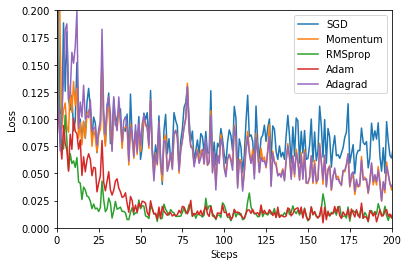
?
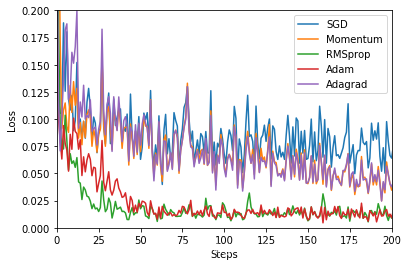
一个有趣的现象是Adagrad和Momentum走势非常相似,有空可以思考一下。
图片版权:?Alec Radford
第一张图是损失函数的等高线: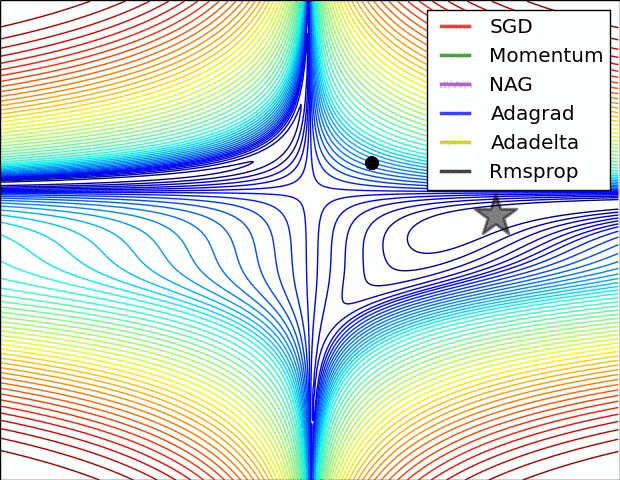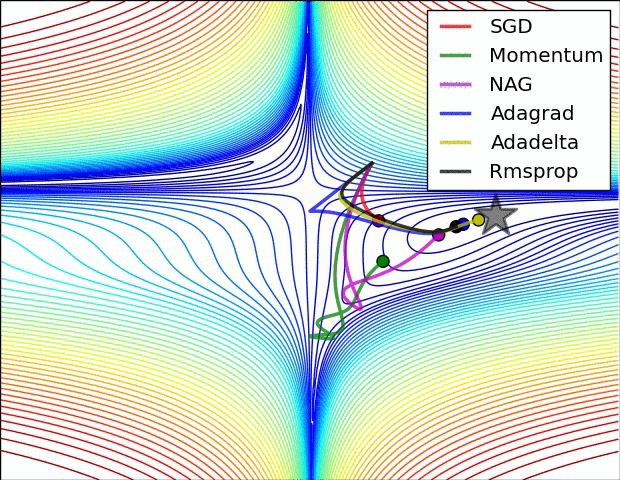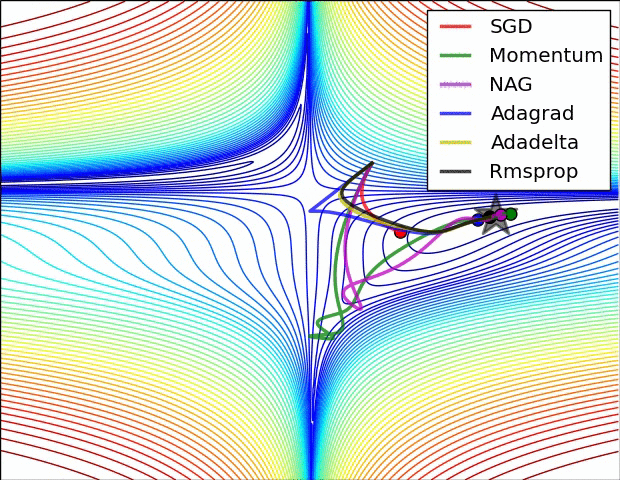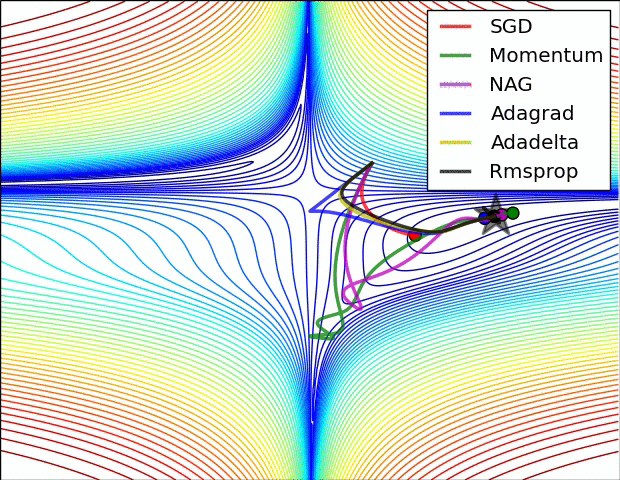
第二张图是在鞍点处的学习情况,注意SGD很难突破对称性,一直卡在顶部。而RMSProp之类的方法能够看到马鞍方向有很低的梯度。因为在RMSProp更新方法中的分母项,算法提高了在该方向的有效学习率,使得RMSProp能够继续前进: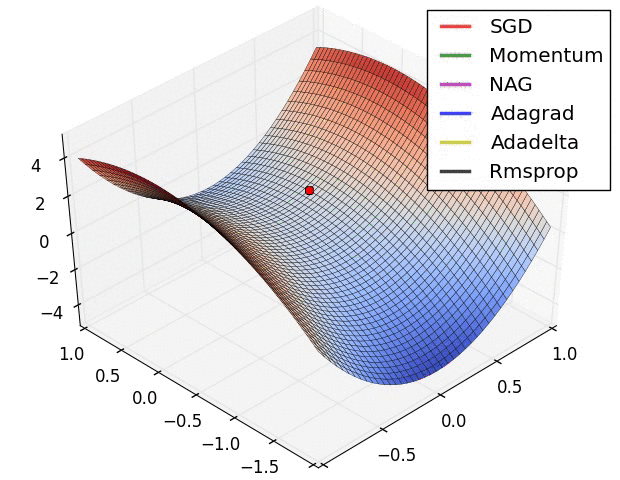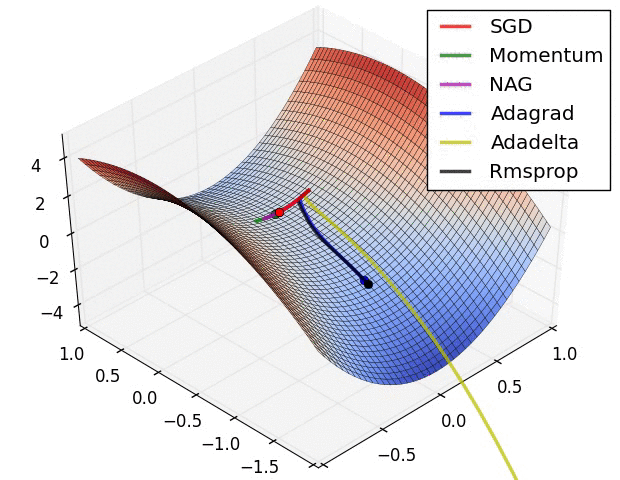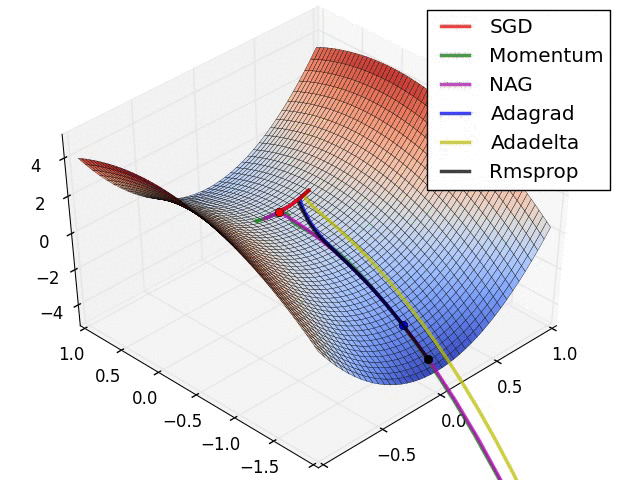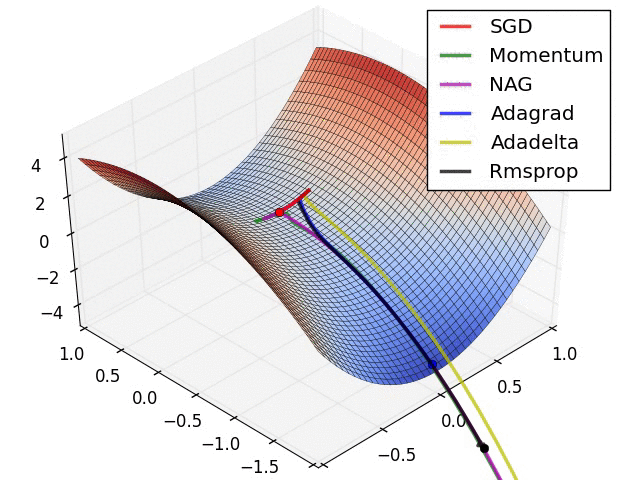
在线客服
电话咨询


官方微信
返回顶部



